
近日,365英国上市孙忠贵教授,以第一作者身份在《The Visual Computer》上发表题为《Dynamic-static hybrid dictionary learning: enhancing deep K-SVD for image denoising and beyond》的研究成果,机器视觉与学习小组研究生姚婧和重庆邮电大学博士生张灿分别为第二作者和第三作者。该成果的刊发标志着我院在图像稀疏表示与深度学习交叉领域取得新的研究进展。
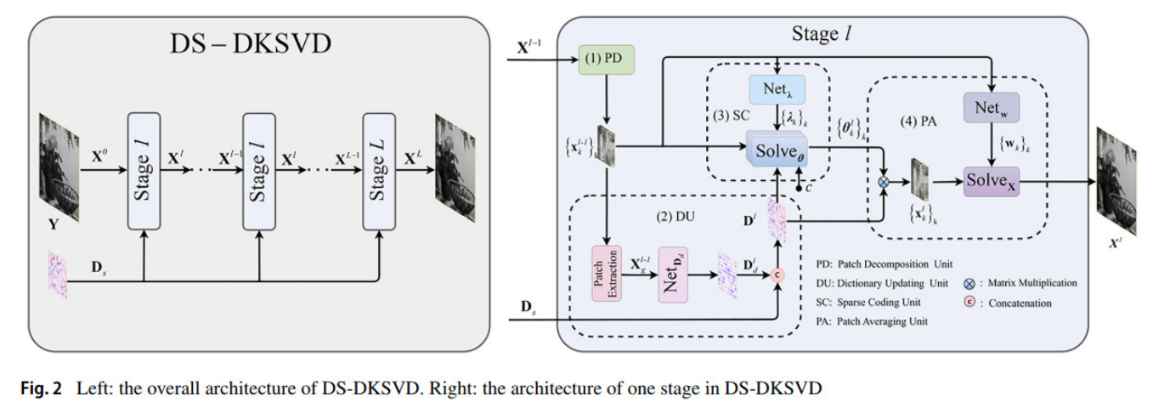
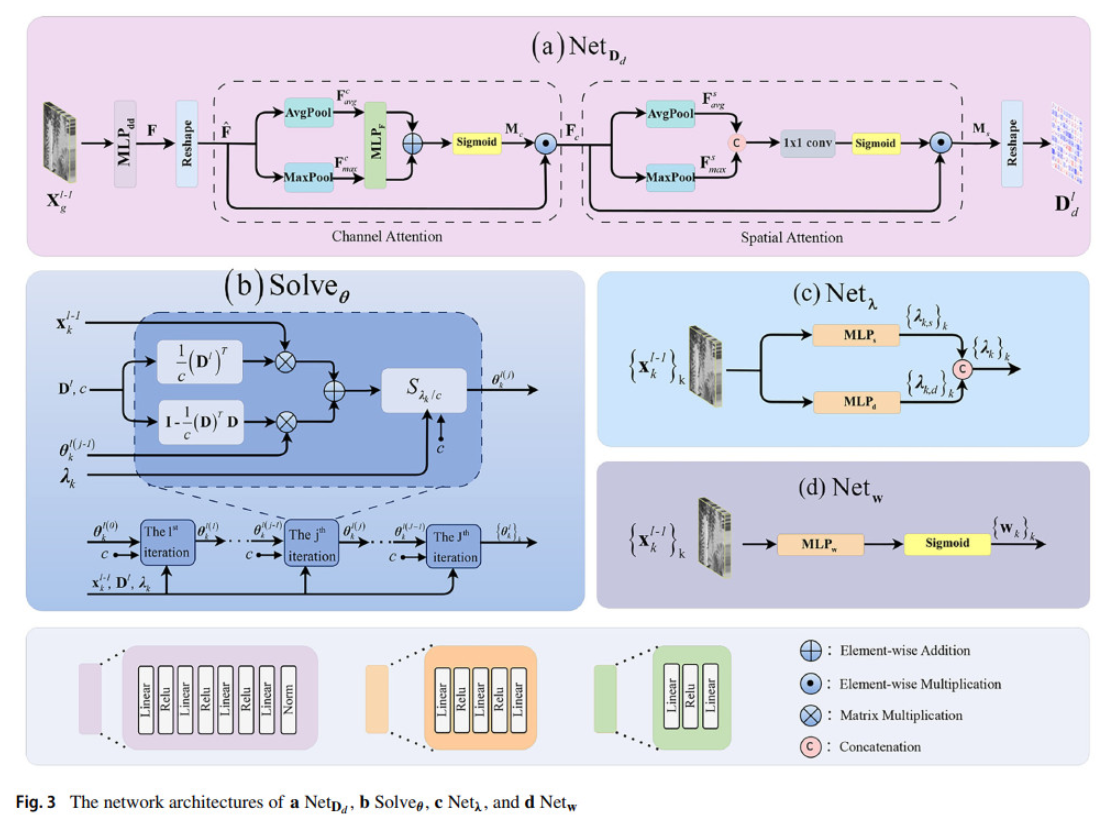
针对Deep K-SVD方法在推理过程中依赖静态参数、难以适应复杂图像场景的问题,该研究提出了一种动态-静态混合字典学习模型(DS-DKSVD)。其主要特点如下:一是动态-静态混合字典架构:与DKSVD采用单一静态字典不同,DS-DKSVD的字典由静态和动态两部分构成。二是自适应图像块加权策略:在图像重建的图像块平均过程中,DS-DKSVD摒弃了DKSVD中所有图像块共用一组固定权重的做法,转而采用一个独立的子网络为每个图像块动态学习其对应的权重。三是更完整的理论可解释性:与基于卷积字典学习的CDicL类方法(如DCDicL、CSCNet)仅保留稀疏性约束不同,DS-DKSVD同时保留了传统K-SVD的两大核心先验——线性性与稀疏性。这使得该模型在继承经典方法理论可解释性的同时,也为其在去噪任务之外的跨领域应用提供了可能。
实验表明,DS-DKSVD在非盲和盲图像去噪任务中均取得良好性能:较原始DKSVD提升0.46 dB(PSNR),较其改进版本AKSVD提升0.42 dB。在更具挑战性的盲去噪任务中,面对与训练集不同模态的深度图像数据集,DS-DKSVD仍展现出优异的泛化能力。此外,初步的图像分类实验也验证了该方法在去噪任务之外的适用潜力。